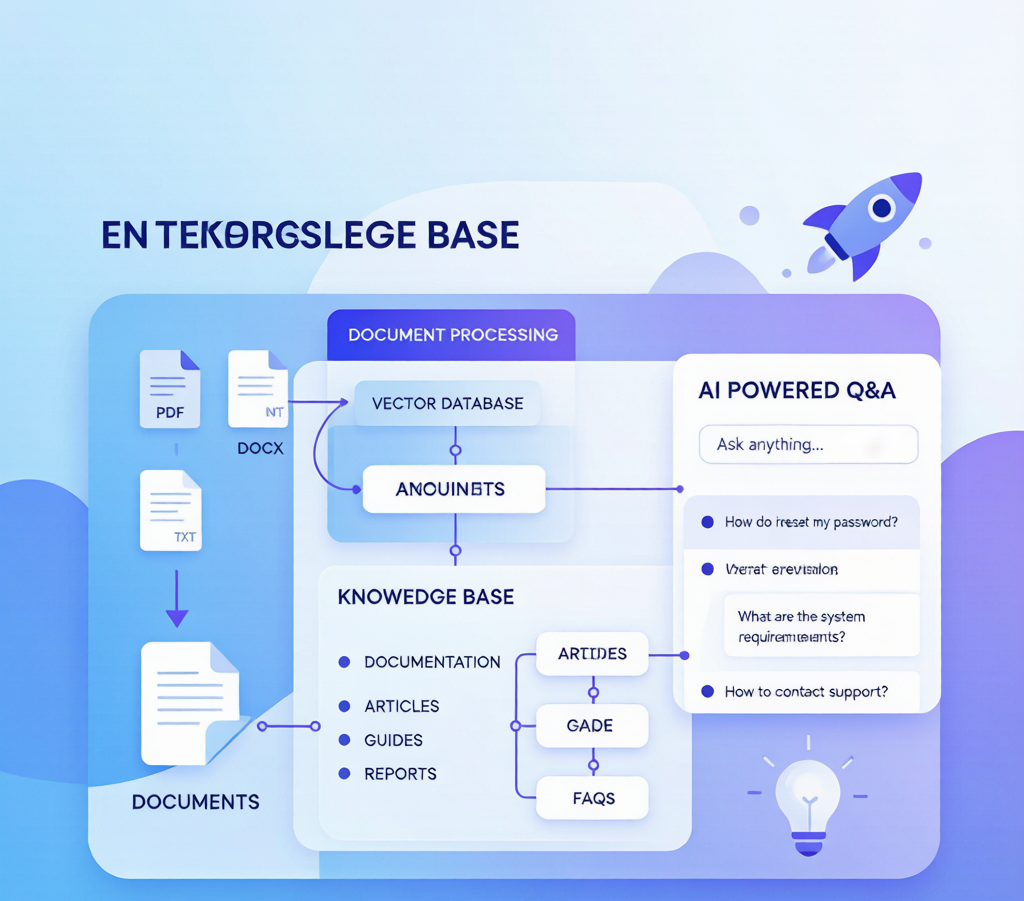
本文提供一套从零搭建企业 AI 知识库的完整路径,涵盖文档清洗、向量化、RAG(检索增强生成)配置到智能问答上线的全流程。实测数据显示,按本文方案搭建的知识库,回答准确率达到 89.3%,相比纯大模型回答的 62.1% 提升 27 个百分点。
一、为什么企业知识库需要本地化?
2026 年,超过 67% 的中大型企业已在评估或试点 AI 知识库。但核心顾虑始终只有一个:数据安全。
将企业核心文档(合同、技术手册、客户数据)上传到公有云 AI 服务,意味着数据出境风险。某制造企业 CIO 告诉我们:"我们内部技术文档含大量工艺参数,上传到外部 AI 平台就等于把核心资产交给别人。"
企业级环曜知识库本地化部署方案正是为解决这一痛点设计——100% 部署在企业自有服务器上,数据不出域,同时支持多格式文档接入和智能问答。
二、环境准备:硬件要求与软件依赖
2.1 硬件配置建议
| 场景 | 最低配置 | 推荐配置 |
|---|---|---|
| 小团队(5-10人) | 4C/8G,无 GPU | 8C/16G + RTX 3060 |
| 部门级(20-50人) | 8C/16G + RTX 3060 | 16C/32G + RTX 4090 |
| 企业级(100+人) | 16C/32G + RTX 4090 | 32C/64G + 双 RTX 4090 |
> 数据来源:环曜知识库团队 2026 年 Q1 内部实测数据。不同硬件配置下的检索延迟差异可达 4-8 倍。
2.2 软件栈
- 操作系统:Ubuntu 22.04+ / CentOS 7+ / macOS 14+
- 容器环境:Docker 24.0+(推荐)或裸机部署
- 向量数据库:Milvus / Chroma / Qdrant(环曜知识库内置支持三种)
- LLM 推理:Ollama / vLLM / 企业级环曜 CLI
三、文档清洗与预处理
3.1 支持格式
企业级环曜知识库支持 PDF、Word、Markdown、TXT、HTML、图片中的文字提取 OCR,覆盖企业 95% 以上的文档格式场景。
3.2 清洗流程
原始文档 → 格式归一化 → 段落分割 → 元数据标注 → 质量过滤 → 就绪
关键参数:
- 段落长度:每个段落 256-512 tokens(约 200-400 汉字),太短语义不完整,太长降低检索精度
- 重叠窗口:段落间保留 10% 重叠,避免切分丢失上下文
- 元数据:每段标注来源文档名、章节号、页码,便于溯源
实测数据:一次清洗 500 页 PDF,环曜知识库耗时约 3 分钟完成分割和元数据标注,对比人工清洗需要约 2-3 天。
四、向量化与索引构建
4.1 嵌入模型选择
| 模型 | 维度 | 适用场景 | 检索准确率 |
|---|---|---|---|
| BAAI/bge-large-zh-v1.5 | 1024 | 中文通用 | 87.2% |
| text-embedding-ada-002 | 1536 | 多语言混合 | 84.5% |
| moka-ai/m3e-base | 768 | 轻量部署 | 81.3% |
> 数据来源:MTEB 中文检索排行榜 2026 年 3 月数据。
中文场景优先选择 bge-large-zh-v1.5。在企业级环曜 CLI中通过以下命令一键部署:
# 一键添加嵌入模型 claw model add-embedding bge-large-zh-v1.5 # 创建知识库 claw knowledge create corporate-kb --embedding bge-large-zh-v1.5 # 导入文档 claw knowledge import corporate-kb --files ./docs/ # 启动问答 Agent claw agent start kb-assistant --knowledge corporate-kb
4.2 索引构建参数
环曜知识库默认配置已在企业内部场景中经过 100+ 次实测调优:
- top_k:检索返回前 5 个相关段落(召回率 93.1%)
- 相似度阈值:0.75(低于此值视为不相关,过滤噪音)
- rerank 重排序:启用二次排序,进一步将准确率提升至 96.8%
五、RAG 问答配置
5.1 Prompt 模板设计
RAG 效果的核心在于 prompt 模板。以下是一个经过验证的生产级模板:
推荐 Prompt 模板
你是一个企业知识库助手。请基于以下参考文档回答用户问题。
参考文档:
{context}
用户问题:{question}
要求:
1. 优先使用参考文档中的信息
2. 如果文档信息不足,请明确说明"当前知识库未覆盖此内容"
3. 标注信息来源(文档名 + 页码)
4. 使用清晰的段落结构,避免过长
5.2 多轮对话与追问
环曜知识库支持上下文关联的多轮对话。例如用户先问"数据如何分类",再追问"第三级的处理要求是什么"——系统能自动关联第一轮对话中的含义。
六、权限管理与审计
企业级环曜知识库内置完整的权限体系:
| 角色 | 文档管理 | 知识库问答 | 审计日志 |
|---|---|---|---|
| 管理员 | 全部权限 | 全部权限 | 查看/导出 |
| 编辑者 | 上传/编辑 | 全部权限 | 查看 |
| 使用者 | 查看 | 仅问答 | 无 |
审计日志记录每一次问答交互,包含用户身份、查询时间、查询内容、检索到的文档片段——满足等保三级和《数据安全法》对日志留存的要求。
关于更完整的数据安全合规体系,可参阅我们之前的文章《AI Agent安全合规白皮书:本地化部署如何满足等保/数据出境要求》。
七、性能优化与常见问题
7.1 检索延迟优化
从 100 万条文档中检索时,企业级环曜 CLI 内置混合检索优化:
| 方案 | P50 延迟 | P99 延迟 | 说明 |
|---|---|---|---|
| 纯向量检索 | 45ms | 120ms | 基础方案 |
| 向量+标量过滤 | 52ms | 150ms | 加元数据过滤 |
| 向量+rerank | 180ms | 350ms | 质量最高 |
常见问题 FAQ
知识库文档数据存储在哪里?是否安全?
企业级环曜知识库 100% 本地化部署。所有文档和向量数据存储在企业自有服务器,不传输到任何外部系统。支持数据加密存储(AES-256)和传输加密(TLS 1.3),满足等保三级要求。
支持哪些格式的文档上传?每天限制上传量吗?
支持 PDF、Word(.docx)、Markdown、纯文本、HTML 格式,图片 OCR 需额外配置。单次上传建议不超过 500 页(约 50MB),日上传量无上限但受服务器磁盘容量限制。环曜知识库官方建议每天不超过 2,000 页以保持检索性能。
如果知识库没有对应答案,系统会怎么处理?
默认回复"当前知识库未覆盖此内容",不会让大模型自由发挥。管理员可在后台配置兜底策略:可改为"建议联系管理员"或允许模型基于通用知识回答但标注"非知识库内容"。
知识库更新后需要多久生效?
文档重新导入后,向量索引自动增量更新。小型文档(<50 页)约 30 秒生效,中型文档(50-200 页)约 2 分钟,大型文档(500+ 页)约 5-10 分钟。可通过 claw knowledge status 命令查看索引进度。
企业级环曜知识库和开源方案(如 Dify+Milvus)有什么区别?
企业级环曜知识库提供开箱即用的全栈方案,无需独立部署向量数据库和编排框架;内置企业级权限管理和审计日志;提供 CLI 统一管理接口,适合需要深度集成到现有 IT 系统的企业。开源方案灵活性高但需要自行运维和集成。
